-
DBMS Tutorial
- dbms-tutorial
- what-is-database
- types-of-databases
- what-is-rdbms
- dbms-vs-rdbms
- dbms-vs-file-system
- dbms-architecture
- three-schema-architecture
- data-models
- data-model-schema
- data-independence
- dbms-language
- acid-properties-in-dbms
Data modeling
- er-model-concept
- notation-for-er-diagram
- er-design-issues
- mapping-constraints
- dbms-keys
- dbms-generalization
- dbms-specialization
- dbms-aggregation
- convert-er-into-table
- relationship-of-higher-degree
Relational data Model
- relational-model-concept
- relational-algebra
- join-operation
- integrity-constraints
- relational-calculus
Normalization
- functional-dependency
- inference-rule
- dbms-normalization
- dbms-1nf
- dbms-2nf
- dbms-3nf
- dbms-bcnf
- dbms-4nf
- dbms-5nf
- relational-decomposition
- multivalued-dependency
- join-dependency
- inclusion-dependence
- canonical-cover
Transaction Processing
- transaction
- transaction-property
- states-of-transaction
- dbms-schedule
- testing-of-serializability
- conflict-schedule
- view-serializability
- recoverability-of-schedule
- failure-classification
- log-based-recovery
- dbms-checkpoint
- deadlock-in-dbms
Concurrency Control
- concurrency-control
- lock-based-protocol
- time-stamping-protocol
- validation-based-protocol
- thomas-write-rule
- multiple-granularity
- recovery-concurrent-transaction
File organization
- file-organization
- sequential-file-organization
- heap-file-organization
- hash-file-organization
- b+-file-organization
- dbms-isam
- cluster-file-organization
Indexing and B+ Tree
Hashing
RAID
Misc
- decomposition-algorithms
- storage-system-in-dbms
- data-dictionary-storage
- file-organization-storage
- selection-of-raid-levels
- bitmap-indexing
- buffer-replacement-strategies
- database-buffer
- estimating-query-cost
- query-processing-in-dbms
- evaluation-of-expressions
- external-sort-merge-algorithm
- hash-join-algorithm
- materialization-in-query-processing
- merge-join-algorithm
- nested-loop-join-algorithm
- selection-operation-in-query-processing
- double-pipelined-join-algorithm
- implementation-of-pipelining
- pipelining-in-query-processing
- advanced-query-optimization
- transforming-relational-expressions
- candidate-key
- closure-of-an-attribute
- questions-on-boyce-codd-normal-form
- questions-on-normalization
- questions-on-third-normal-form
- equivalence-of-functional-dependency
- referential-integrity-constraint
- questions-on-lossy-and-lossless-decomposition
- lossy-or-lossless-decomposition-(second-method)
- questions-to-identify-normal-form
- types-of-relationship-in-database-table
- candidate-key-in-dbms
- primary-key-in-dbms
- super-key-in-dbms
- alternate-key-in-dbms
- composite-key-in-dbms
- foreign-key-in-dbms
- surrogate-key-in-dbms
- unique-key-in-dbms
- purpose-of-normalization
- commit-vs-rollback-in-sql
- ddl-vs-dml
- denormalization-in-databases
- er-model-vs-relational-model
SQL Introduction
- sql-introduction
- characteristics-of-sql
- advantage-of-sql
- sql-datatype
- sql-command
- sql-operator
- sql-table
- sql-select-statement
- sql-insert-statement
- sql-update-statement
- sql-delete-statement
- sql-view
- sql-index
- sql-sub-queries
- sql-clauses
- sql-aggregate-function
- sql-join
- sql-set-operation
DBMS MCQ
Interview Questions
External Sort-Merge AlgorithmTill now, we saw that sorting is an important term in any database system. It means arranging the data either in ascending or descending order. We use sorting not only for generating a sequenced output but also for satisfying conditions of various database algorithms. In query processing, the sorting method is used for performing various relational operations such as joins, etc. efficiently. But the need is to provide a sorted input value to the system. For sorting any relation, we have to build an index on the sort key and use that index for reading the relation in sorted order. However, using an index, we sort the relation logically, not physically. Thus, sorting is performed for cases that include: Case 1: Relations that are having either small or medium size than main memory. Case 2: Relations having a size larger than the memory size. In Case 1, the small or medium size relations do not exceed the size of the main memory. So, we can fit them in memory. So, we can use standard sorting methods such as quicksort, merge sort, etc., to do so. For Case 2, the standard algorithms do not work properly. Thus, for such relations whose size exceeds the memory size, we use the External Sort-Merge algorithm. The sorting of relations which do not fit in the memory because their size is larger than the memory size. Such type of sorting is known as External Sorting. As a result, the external-sort merge is the most suitable method used for external sorting. External Sort-Merge AlgorithmHere, we will discuss the external-sort merge algorithm stages in detail: In the algorithm, M signifies the number of disk blocks available in the main memory buffer for sorting. Stage 1: Initially, we create a number of sorted runs. Sort each of them. These runs contain only a few records of the relation. In Stage 1, we can see that we are performing the sorting operation on the disk blocks. After completing the steps of Stage 1, proceed to Stage 2. Stage 2: In Stage 2, we merge the runs. Consider that total number of runs, i.e., N is less than M. So, we can allocate one block to each run and still have some space left to hold one block of output. We perform the operation as follows: After completing Stage 2, we will get a sorted relation as an output. The output file is then buffered for minimizing the disk-write operations. As this algorithm merges N runs, that's why it is known as an N-way merge. However, if the size of the relation is larger than the memory size, then either M or more runs will be generated in Stage 1. Also, it is not possible to allocate a single block for each run while processing Stage 2. In such a case, the merge operation process in multiple passes. As M-1 input buffer blocks have sufficient memory, each merge can easily hold M-1 runs as its input. So, the initial phase works in the following way:
Estimating cost for External Sort-Merge MethodThe cost analysis of external sort-merge is performed using the above-discussed stages in the algorithm:
Every pass read and write each block of the relation only once. But with two exceptions:
Neglecting such small exceptions, the total number of block transfers for external sorting comes out: b r (2 Γ log M-1 (b r /M) ˥ + 1) We need to add the disk seek cost because each run needs seeks reading and writing data for them. If in Stage 2, i.e., the merge phase, each run is allocated with bb buffer blocks or each run reads bb data at a time, then each merge needs [br /bb] seeks for reading the data. The output is written sequentially, so if it is on the same disk as input runs, the head will need to move between the writes of consecutive blocks. Therefore, add a total of 2[br /bb] seeks for each merge pass and the total number of seeks comes out: 2 Γ b r /M ˥ + Γb r /b b ˥(2ΓlogM-1(b r /M)˥ - 1) Thus, we need to calculate the total number of disk seeks for analyzing the cost of the External merge-sort algorithm. Example of External Merge-sort AlgorithmLet's understand the working of the external merge-sort algorithm and also analyze the cost of the external sorting with the help of an example. 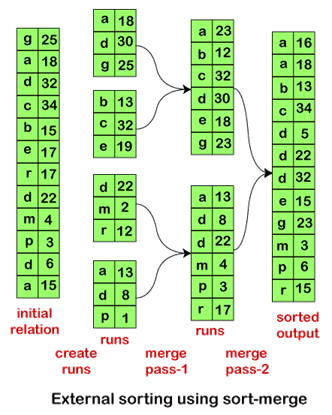 Suppose that for a relation R, we are performing the external sort-merge. In this, assume that only one block can hold one tuple, and the memory can hold at most three blocks. So, while processing Stage 2, i.e., the merge stage, it will use two blocks as input and one block for output. Next TopicHash Join Algorithm
|