When we fit a regression model to a dataset, we’re often interested in how well the regression model “fits” the dataset. Two metrics commonly used to measure goodness-of-fit include R-squared (R2) and the standard error of the regression, often denoted S.
This tutorial explains how to interpret the standard error of the regression (S) as well as why it may provide more useful information than R2.
Standard Error vs. R-Squared in Regression
Suppose we have a simple dataset that shows how many hours 12 students studied per day for a month leading up to an important exam along with their exam score:

If we fit a simple linear regression model to this dataset in Excel, we receive the following output:
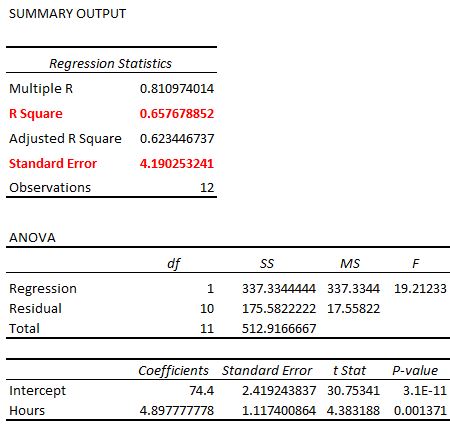
R-squared is the proportion of the variance in the response variable that can be explained by the predictor variable. In this case, 65.76% of the variance in the exam scores can be explained by the number of hours spent studying.
The standard error of the regression is the average distance that the observed values fall from the regression line. In this case, the observed values fall an average of 4.89 units from the regression line.
If we plot the actual data points along with the regression line, we can see this more clearly:

Notice that some observations fall very close to the regression line, while others are not quite as close. But on average, the observed values fall 4.19 units from the regression line.
The standard error of the regression is particularly useful because it can be used to assess the precision of predictions. Roughly 95% of the observation should fall within +/- two standard error of the regression, which is a quick approximation of a 95% prediction interval.
If we’re interested in making predictions using the regression model, the standard error of the regression can be a more useful metric to know than R-squared because it gives us an idea of how precise our predictions will be in terms of units.
To illustrate why the standard error of the regression can be a more useful metric in assessing the “fit” of a model, consider another example dataset that shows how many hours 12 students studied per day for a month leading up to an important exam along with their exam score:

Notice that this is the exact same dataset as before, except all of the values are cut in half. Thus, the students in this dataset studied for exactly half as long as the students in the previous dataset and received exactly half the exam score.
If we fit a simple linear regression model to this dataset in Excel, we receive the following output:
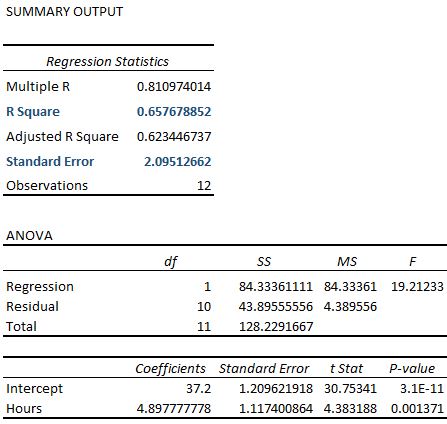
Notice that the R-squared of 65.76% is the exact same as the previous example.
However, the standard error of the regression is 2.095, which is exactly half as large as the standard error of the regression in the previous example.
If we plot the actual data points along with the regression line, we can see this more clearly:
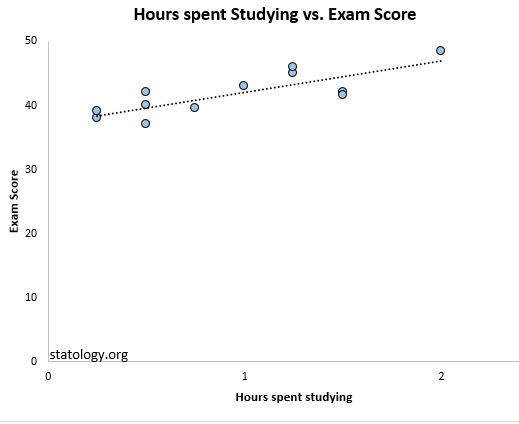
Notice how the observations are packed much more closely around the regression line. On average, the observed values fall 2.095 units from the regression line.
So, even though both regression models have an R-squared of 65.76%, we know that the second model would provide more precise predictions because it has a lower standard error of the regression.
The Advantages of Using the Standard Error
The standard error of the regression (S) is often more useful to know than the R-squared of the model because it provides us with actual units. If we’re interested in using a regression model to produce predictions, S can tell us very easily if a model is precise enough to use for prediction.
For example, suppose we want to produce a 95% prediction interval in which we can predict exam scores within 6 points of the actual score.
Our first model has an R-squared of 65.76%, but this doesn’t tell us anything about how precise our prediction interval will be. Luckily we also know that the first model has an S of 4.19. This means a 95% prediction interval would be roughly 2*4.19 = +/- 8.38 units wide, which is too wide for our prediction interval.
Our second model also has an R-squared of 65.76%, but again this doesn’t tell us anything about how precise our prediction interval will be. However, we know that the second model has an S of 2.095. This means a 95% prediction interval would be roughly 2*2.095= +/- 4.19 units wide, which is less than 6 and thus sufficiently precise to use for producing prediction intervals.
Further Reading
Introduction to Simple Linear Regression
What is a Good R-squared Value?