-
MySQL Tutorial
- mysql-tutorial
- mysql-features
- mysql-versions
- mysql-data-types
- mysql-variables
- install-mysql
- mysql-connection
MySQL Workbench
User Management
MySQL Database
- mysql-create-database
- mysql-select-database
- mysql-show-databases
- mysql-drop-database
- mysql-copy-database
Table & Views
- mysql-create-table
- mysql-alter-table
- mysql-show-tables
- mysql-rename-table
- mysql-truncate-table
- mysql-describe-table
- mysql-drop-table
- mysql-temporary-table
- mysql-copy-table
- mysql-repair-table
- mysql-add/delete-column
- mysql-show-columns
- mysql-rename-column
- mysql-views
- mysql-table-locking
- mysql-account-lock
MySQL Queries
- mysql-select-record
- mysql-replace
- insert-on-duplicate-key-update
- mysql-insert-ignore
- insert-into-select
MySQL Indexes
- mysql-create-index
- mysql-drop-index
- mysql-show-indexes
- mysql-unique-index
- mysql-clustered-index
- mysql-clustered-vs-non-clustered-index
MySQL Clauses
MySQL Privileges
Control Flow Function
MySQL Conditions
- mysql-and
- mysql-or
- mysql-and-or
- mysql-boolean
- mysql-like
- mysql-in
- mysql-any
- mysql-exists
- mysql-not
- mysql-not-equal
- mysql-is-null
- mysql-is-not-null
- mysql-between
MySQL Join
- mysql-join
- mysql-inner-join
- mysql-left-join
- mysql-right-join
- mysql-cross-join
- mysql-self-join
- mysql-delete-join
- mysql-update-join
- mysql-equijoin
- mysql-natural-join
- left-join-vs-right-join
- mysql-union-vs-join
MySQL Key
MySQL Triggers
- mysql-trigger
- mysql-create-trigger
- mysql-show-trigger
- mysql-drop-trigger
- before-insert-trigger
- after-insert-trigger
- mysql-before-update-trigger
- mysql-after-update-trigger
- mysql-before-delete-trigger
- mysql-after-delete-trigger
Aggregate Functions
- mysql-aggregate-functions
- mysql-count()
- mysql-sum()
- mysql-avg()
- mysql-min()
- mysql-max()
- mysql-group_concat()
- mysql-first()
- mysql-last()
MySQL Misc
- mysql-comments
- export-import-database
- import-csv-file-in-database
- export-table-to-csv
- mysql-subquery
- mysql-derived-table
- mysql-uuid
- lead-and-lag-function
- mysql-cte
- mysql-on-delete-cascade
- mysql-upsert
- mysql-commands-cheat-sheet
- mysql-transaction
- mysql-partitioning
- mysql-row_number()
- mysql-cursor
- mysql-limit
- mysql-stored-function
- mysql-signal-resignal
- number-format-function
- mysql-ranking-functions
- mysql-window-functions
- mysql-union
- union-vs-union-all
- mysql-varchar
- mysql-enum
- mysql-set
- mysql-decimal
- mysql-cast
- mysql-convert()
- mysql-coalesce()
- mysql-wildcards
- mysql-alias
- mysql-functions
- mysql-rollup
- mysql-int
- mysql-today
- mysql-row-count
- prepared-statement
- mysql-literals(constants)
- mysql-date-time
- mysql-procedure
- mysql-minus
- mysql-intersect
- mysql-storage-engines
- mysql-explain
- mysql-sequence
- mysql-json
- mysql-standard-deviation
- how-to-select-nth-highest-record
- find-duplicate-records
- delete-duplicate-records
- mysql-select-random-records
- mysql-extract
- mysql-processlist
- mysql-bit
- change-column-type
- mysql-reset-auto-increment
- mysql-interval
- login-with-different-user
MySQL Globalisation
Regular Expressions
- regular-expressions
- mysql-rlike
- not-like-operator
- not-regexp-operator
- regexp-operator
- regexp_instr()-function
- regexp_like()-function
- regexp_replace()-function
- regexp_substr()-function
FULLTEXT Search
- mysql-fulltext-search
- natural-language-fulltext-search
- boolean-fulltext-search
- query-expansion-fulltext-search
- ngram-fulltext-parser
Differences
- mysql-vs-mongodb
- mysql-vs-ms-sql-server
- mysql-vs-oracle
- mariadb-vs-mysql
- postgresql-vs-mysql
- mysql-vs-sql
- table-vs-view
- delete-vs-truncate-command
- database-vs-schema
- primary-key-vs-foreign-key
- primary-key-vs-unique-key
- primary-key-vs-candidate-key
Interview Questions
MySQL ngram Full-Text ParserIn this article, we are going to learn the use of MySQL ngram full-text parser that supports full-text searches for ideographic languages such as Japanese, Chinese, and Korean. The built-in MySQL full-text parser uses delimiter as a white space between words that determines the beginning and end of words. The full-text parser has a limitation when working with ideographic languages such as Japanese, Chinese, and Korean because they do not use word delimiters. MySQL provides the ngram full-text parser to overcome this issue. After MySQL version 5, MySQL provides the ngram full-text parser as a built-in server plugin. Similar to other built-in plugins, MySQL loads this plugin automatically when the database server is started. The ngram full-text parser is supported for both InnoDB and MyISAM storage engines in MySQL. According to its definition in MySQL, an ngram is a contiguous sequence of a number of characters from a given sequence of text. Its main function is to tokenize a sequence of text into a contiguous sequence of n characters. For example, by using the ngram full-text parser, we can tokenize the string "java" for different values of N as follows: Creating a FULLTEXT Index with the ngram ParserWe can create a FULLTEXT index with the ngram parser by specifying WITH PARSER ngram in the CREATE TABLE, ALTER TABLE, or CREATE INDEX statement. Consider the following example that creates a table named "articles" and add the title and body column with an ngram full-text parser. Next, we will use the SET NAMES statement that sets the character set to UTF8MB4 as below: Next, insert sample data (Simplified Chinese text) into this table as below: Fourth, we will use the below statement to see how the ngram tokenizes the data: We will get the below result: 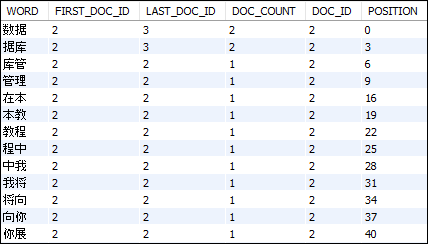 This type of statement helps in troubleshooting purposes. For example, if we search a word that does not include it, then the word assumes as a stopword and may not be indexed, or it could be another reason. Setting ngram Token SizeIn the previous example, we can see that by default, the token size (n) in the ngram is 2. If we want to change the default token size, we need to use the ngram_token_size configuration option that's value ranges between 1 and 10. It is to note that the smaller token size makes a smaller full-text search index and also provides fast search. The ngram_token_size is a read-only variable, so we can set its value using the below two options only: 1. In the start-up string: 2. In the configuration file: Space handling in ngram ParserSpace is eliminated in the ngram parser when parsing. For example:
ngram Parser Phrase SearchMySQL converted the phrase searches into ngram phrase searches. For example, we have a phrase search "abc" that is converted to "ab bc", returns results containing "abc" and "ab bc". If we have a search phrase "abc def" that is converted to "ab bc de ef", it returns results containing "abc def" and "ab bc de ef". It does not return the document that contains "abcdef". The below statement displays the search for the phrase ?? in the articles table: Here is the result:  Processing different search mode with ngramHere, we will process the search result with ngram using the below modes: Natural Language ModeThe NATURAL LANGUAGE search mode converted the search term to a union of ngram values. For example, if the token size is 2, the search term "mysql" can be converted into my ys sq and ql. See the below statement: We will get the desired result:  Boolean ModeThe Boolean search mode converted the search term to an ngram phrase search. See the below statement: We will get the desired result:  ngram Parser Wildcard SearchWhen we use wildcard characters for searching in the ngram parser, it may return unexpected results. Because the ngram FULLTEXT index contains only ngrams, that's why it does not know the beginning of terms. The following rules are used to perform a search using ngram full-text indexes with wildcards: 1. If the ngram token size is longer than the prefix term in the wildcard, the query returns all documents that contain ngram tokens starting with the prefix term. For example: We will get the below result:  2. If the ngram token size is shorter than the prefix term in the wildcard, MySQL will convert the prefix term to an ngram phrase and the wildcard operator is ignored. For example We will get the below result where the term "mysql" is converted into ngram phrases: "my" "ys" "sq" "ql".  Handling Stopwords in ngram ParserThe ngram parser compares words for entries in the stopword list. If they are equal, the word is excluded from the index. The ngram parser handled stopword differently. It excludes the tokens that contain stopwords instead of excluding tokens that are equal to the stopword list. For example, if the ngram_token_size is two and the document contains "a,b", then the ngram parser tokenize them as "a," and ",b". If a comma (",") is a stopword, then both "a," and ",b" are excluded because they contain a comma. It is noted that the ngram parser uses the default stopword list in English. If we want to use other languages, we must create our own. Next TopicMySQL vs MongoDB
|